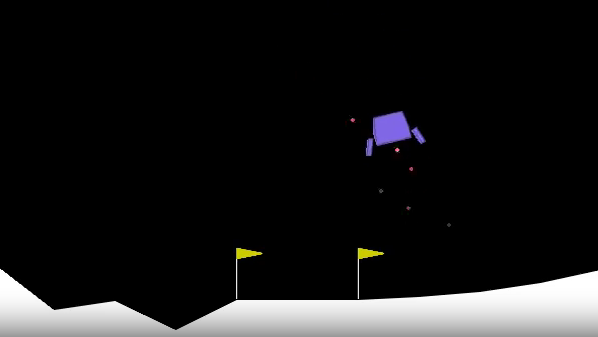
The laws of the ‘land’
Action Space
There are four discrete actions available:
- 0: do nothing
- 1: fire right booster
- 2: fire main engine
- 3: fire left booster
Observation Space
The state is an 8-dimensional vector: the coordinates of the lander in x & y, its linear velocities in x & y, its angle, its angular velocity, and two booleans that represent whether each leg is in contact with the ground or not.
Rewards
After every step a reward is granted. The total reward of an episode is the sum of the rewards for all the steps within that episode.
For each step, the reward:
- is increased/decreased the closer/further the lander is to the landing pad.
- is increased/decreased the slower/faster the lander is moving.
- is decreased the more the lander is tilted (angle not horizontal).
- is increased by 10 points for each leg that is in contact with the ground.
- is decreased by 0.03 points each frame a side engine is firing.
- is decreased by 0.3 points each frame the main engine is firing.
The episode receive an additional reward of -100 or +100 points for crashing or landing safely respectively.
An episode is considered a solution if it scores at least 200 points.
Starting State
The lander starts at the top center of the viewport with a random initial force applied to its center of mass.
Episode Termination
The episode finishes if:
- the lander crashes (the lander body gets in contact with the moon);
- the lander gets outside of the viewport (
xcoordinate is greater than 1); - the lander is not awake — a body which doesn’t move and doesn’t collide with any other body.
Pure Monte Carlo in actor-critic setting (REINFORCE with baseline)
- No advantage normalization
- No bootstrapping
- 1000-length episode truncation
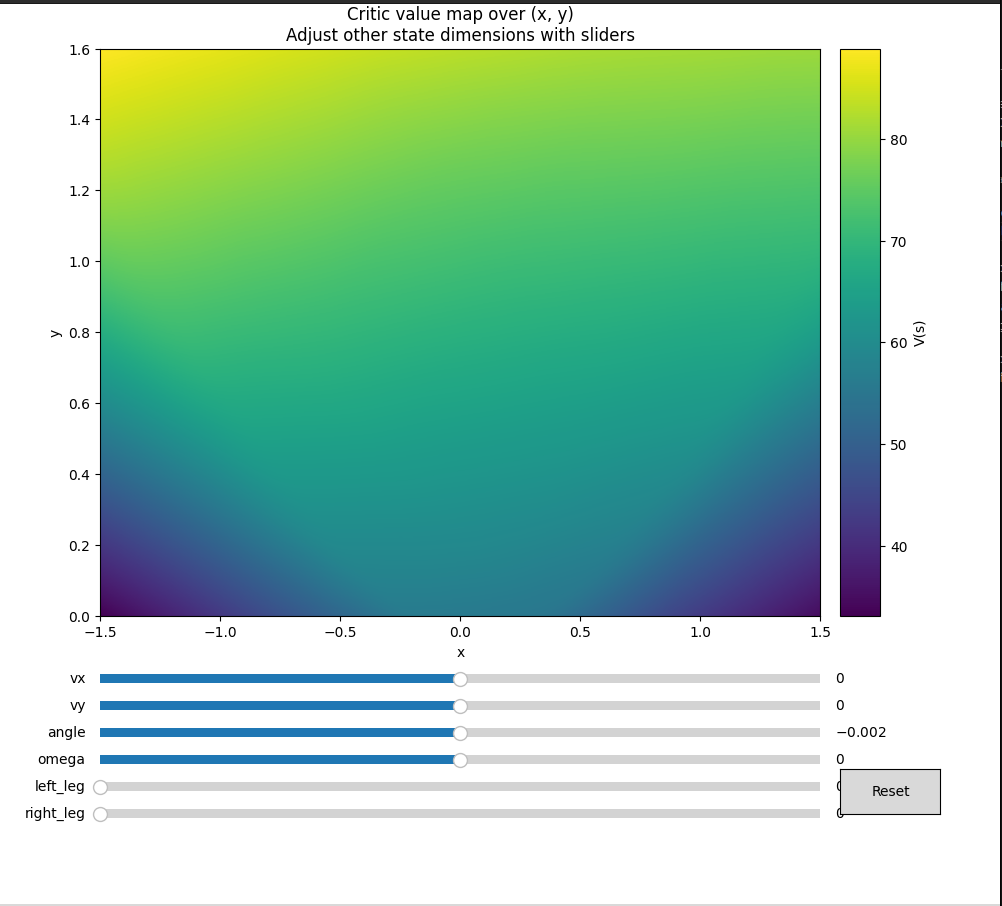
Note: The critic is actually meaningless, since lambda=1 means we are not bootstrapping, it is mainly used for advantage normalization only.
The advantage estimate:
Here, the value function comes from the critic, the return estimate is just the monte-carlo sample (episodic true return).
Since the critic’s value function estimate is treated as a ‘detached’ variable in the semi-gradient step update, we are not actually using it in the gradient step, and so our critic does not influence our actor updates at all. The critic’s job is to simply reduce the variance.
1000 episodes vs 10,000 episodes
Episodes 1000:
10000 episodes — The eagle has landed:
Somewhere between 6000 and 7000, the space ship has figured out it needs to get the episode terminated early.
Analysis of final trained model
What’s the policy that was learned?
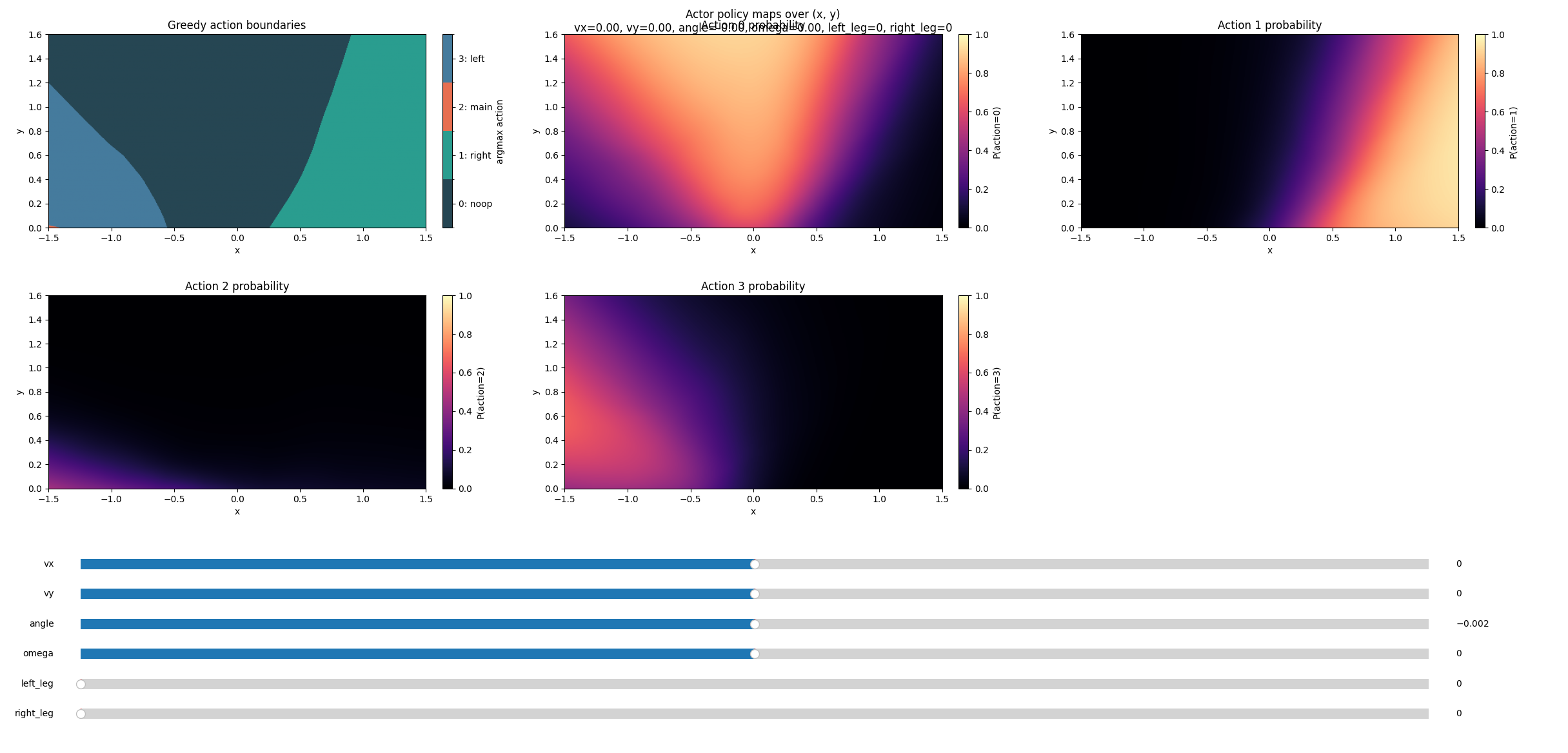
The actor:
The critic (meaningless mostly, but interesting to see what it has learned as episodes accumulate):
Let’s adjust the vx slider, fixing everything else. Observe the preference of actions:
If we make the horizontal velocity toward left, the left booster fires to align itself, and vice versa.
If it’s going too fast down (very negative vy), it will decide to take the penalty of firing the main boosters to avoid crash landing.
If we make the angle negative (the object is tilted to the right/clockwise), the right boosters fire to give it anti-clockwise torque.
If it is tilted anti CW but the angular velocity is in CW direction, it decides it’s not worth firing the boosters — we would land straight if we continue in this trajectory.
Training curves
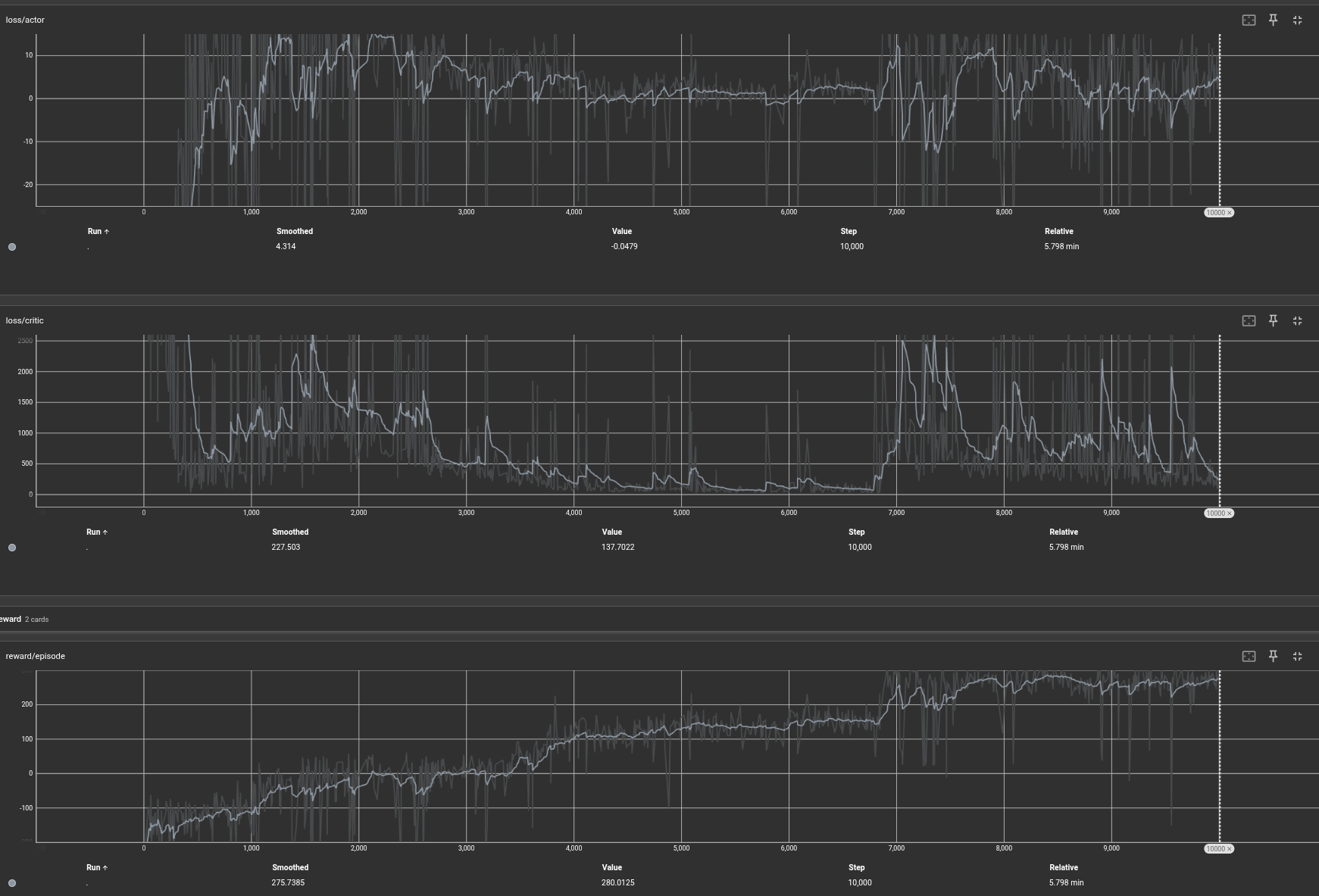
Observe the big jump in reward between episode 6000 and 7000. The space ship figured out it needs to get the episode terminated early — the termination conditions reward structure made early, controlled landing the optimal strategy.
The model learned all of this via this very simple algorithm — pure Monte Carlo policy gradient with a baseline.