

Context & Constraints
The long-term vision involves physical agents capable of executing autonomous household labor. The underlying philosophy assumes that nature-inspired optimization—specifically Reinforcement Learning (RL)—offers the most robust path to generalized movement, rather than hard-coded heuristics.
For this validation project, the objective was deceptively simple: The Coffee Pour.
The robot must:
- Reach for a cup on the XY plane.
- Align the gripper and grasp the object.
- Lift the cup vertically.
- Tilt (pour) the contents into a target vessel.
The Stack:
- Simulation Environment: NVIDIA Isaac Sim (high-fidelity physics).
- Algorithm: PPO (Proximal Policy Optimization) for continuous control.
- Theoretical Basis: Markov Decision Processes (MDPs) derived from standard RL curriculum (Silver et al.).
The primary constraint was sample efficiency. While “brute force” RL works given infinite time, deployment requires a model that converges within a reasonable compute budget.
The Rookie Approach
Initial attempts utilized a standard “Sparse Reward” function—a common pitfall in applied RL. The agent received zero feedback until a specific milestone was hit: +100 for gripping, +200 for lifting, +1000 for pouring.
The result was a non-converging policy. After 50,000 iterations, the reward remained at zero. In a continuous action space with high dimensionality (7-DOF arm), the probability of the agent randomly stumbling upon the precise sequence of actions required to trigger the first positive reward is statistically negligible.
The Pivot to Dense Rewards:
The strategy shifted to dense rewarding (reward shaping). Feedback was provided continuously based on:
- Inverse distance between the End Effector (EE) and the target.
- Orientation alignment of the gripper relative to the XY plane.
While this successfully taught the agent to reach, it failed to generalize to the complex sequential dependencies of lifting and pouring. The agent would optimize for being near the cup but struggled to transition to the next state.
Phase Based Reward
To force the agent through the sequence, a Reward Gating mechanism was implemented. The idea was to activate rewards in phases:
- Phase 1: Distance rewards only.
- Phase 2: Once near the cup, activate alignment and grasp rewards.
The Failure Mode:
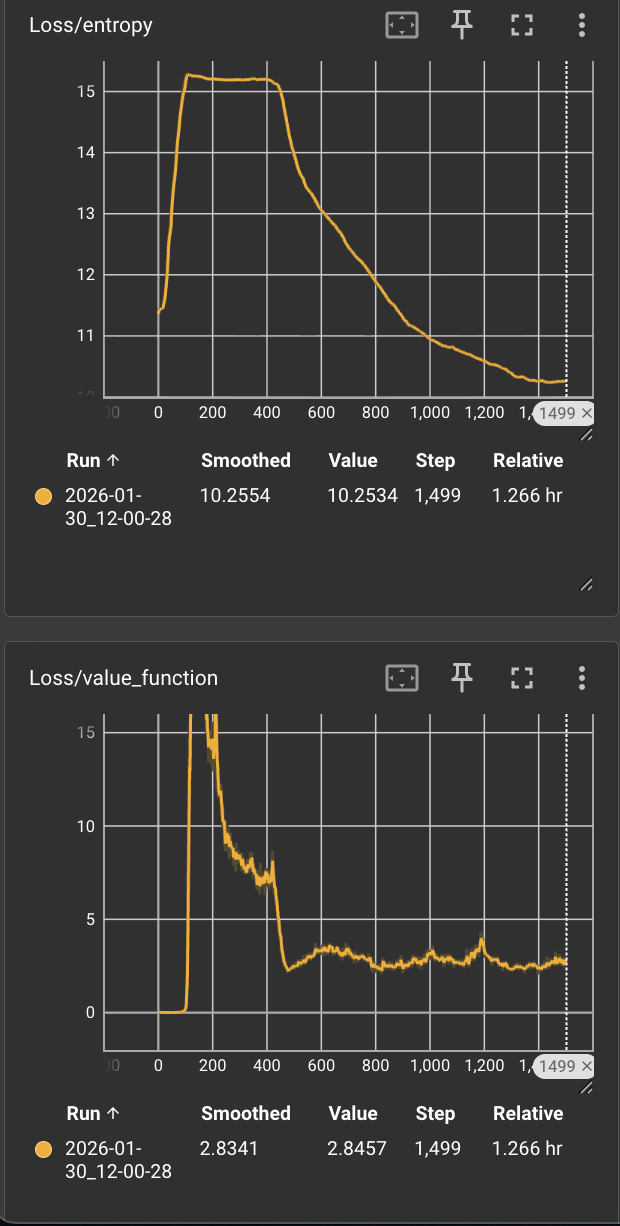
Upon implementing binary phase gating, performance degraded significantly compared to the baseline. Inspection of the loss curves revealed a critical anomaly: at the exact moment of transition from Phase 1 to Phase 2, the Value Function Loss spiked, followed immediately by a spike in Policy Entropy.
Root Cause Analysis:
The spike in Value Function loss indicated that the Critic network’s predictions became wildly inaccurate instantly. The reward landscape changed discontinuously due to the binary switch.
- The Critic lost confidence in its value estimation.
- Because the PPO objective involves an entropy bonus to encourage exploration when the policy is uncertain, the agent reacted to this uncertainty by maximizing entropy.
- Result: The agent abandoned its learned “reaching” behavior and reverted to random exploration, effectively unlearning Phase 1.
- In the graph below you can see that at around 100 the phase transition happened, spiking the loss which lead to increased entropy.
The Solution: Gaussian Gating & Hierarchical RL
Two architectural changes were required to overcome the stability issues and the sequential complexity.
1. Gaussian Reward Gating
To fix the “Wall,” the binary switch was replaced with a Gaussian transition function. Instead of toggling Phase 2 rewards from 0 to 1, the reward signal for Phase 2 was introduced gradually, peaking at the transition point but having a low contributing effect during the bulk of Phase 1.
This smoothed the reward landscape (manifold), allowing the Value Function to approximate the expected return without catastrophic error spikes. The Critic maintained confidence, and the Actor preserved its learned behaviors during the transition.
2. Hierarchical Reinforcement Learning (HRL)
Even with stable gating, a single monolithic policy struggled to master the full reach-grip-lift-pour sequence without complex penalty tuning (which often leads to reward hacking).
The final architecture adopted Hierarchical RL, conceptually similar to a Mixture of Experts (MoE) model.
The Hierarchy:
-
Managerial Policy (The “Router”): A high-level policy trained to observe the state and select which sub-policy to execute.
-
Sub-Policies (The “Experts”): specialized networks trained independently on isolated tasks:
- Reach: Minimizing distance and aligning the gripper.

- Lift: Vertical actuation while maintaining grasp force.
- Pour: Trajectory planning for the tilt mechanism.

The Manager treats the sub-policies as “actions.” This significantly reduced the search space for the Manager, as it only needs to decide what to do, not how to move the joints.
The Results
By decomposing the problem and smoothing the reward signals, the efficiency gains were dramatic.
- Convergence Speed: The HRL approach completed the full task in < 2,000 iterations.
- Comparison: This represents a >96% reduction in training steps compared to the failed sparse reward baseline (50k+ iterations).
- Stability: Value Function loss curves remained bounded during sub-policy transitions, indicating stable transfer of control.
Lessons Learned
- Avoid Discontinuities in Reward Functions: Neural networks approximate continuous functions. Abrupt, binary changes in the reward signal (like binary gating) shatter the Critic’s value estimation, leading to catastrophic forgetting. Gaussian or sigmoid transitions are mandatory for curriculum learning.
- Monolithic Policies are Fragile: For sequential manipulation, asking one neural network to memorize the kinematics of three distinct physical phases is inefficient. HRL decouples decision-making from motor control, mirroring how biological systems likely operate.
- Diagnose via Entropy: When a policy suddenly degrades, check the entropy. A spike usually means the agent is “panicking” because its world model (Value Function) has been invalidated.
